L'IA dans les jeux vidéo - Partie 2
Jusqu’ici, nous avons vu les méthodes ad-hoc qui gèrent manuellement les actions et les stimuli des agents. Ces méthodes fonctionnent bien pour présenter des comportements intelligents à court terme. Cependant, pour concevoir des agents qui peuvent penser à plus long terme, il est nécessaire d’utiliser d’autres méthodes : les algorithmes de planification (planning).
Plutôt que de devoir définir manuellement l’espace des états et les différentes actions pour atteindre un objectif, la planification correspond à effectuer une recherche de solution dans l’espace des états pour atteindre un objectif. En utilisant un algorithme de planification, on va donc rechercher une séquence d’actions qui permet d’arriver à un état voulu.
Présenté pour le pathfinding, l’algorithme A* n’est pas seulement utile pour de la recherche de chemin sur une grille. En effet, on peut aussi l’utiliser pour de la recherche dans l’espace des états et donc pour faire de la planification. L’espace des états est souvent représenté sous la forme d’un arbre où les noeuds sont des états et les branches des actions. Les arbres sont des types de graphes qui sont particulièrement adaptés à la recherche.

Un exemple d’espace des états pour le jeu du morpion représenté sous la forme d’un arbre (seulement un sous ensemble est visible)
L’approche GOAP (Goal Oriented Action Planning)
Cette approche, utilisée pour la première fois en 2005 pour le jeu F.E.A.R, est basée sur l’utilisation d’automates finis ainsi qu’une recherche par A* dans les états de ces automates.
Dans le cas d’un automate fini classique, la logique qui détermine quand et comment transitionner d’un état à un autre doit être spécifiée manuellement ce qui peut être problématique pour des automates avec beaucoup d’états comme on l’a vu précédemment. Avec l’approche GOAP, cette logique est déterminée par le système de planification plutôt que manuellement. Cela permet à l’agent de prendre ses propres décisions pour passer d’un état à un autre.
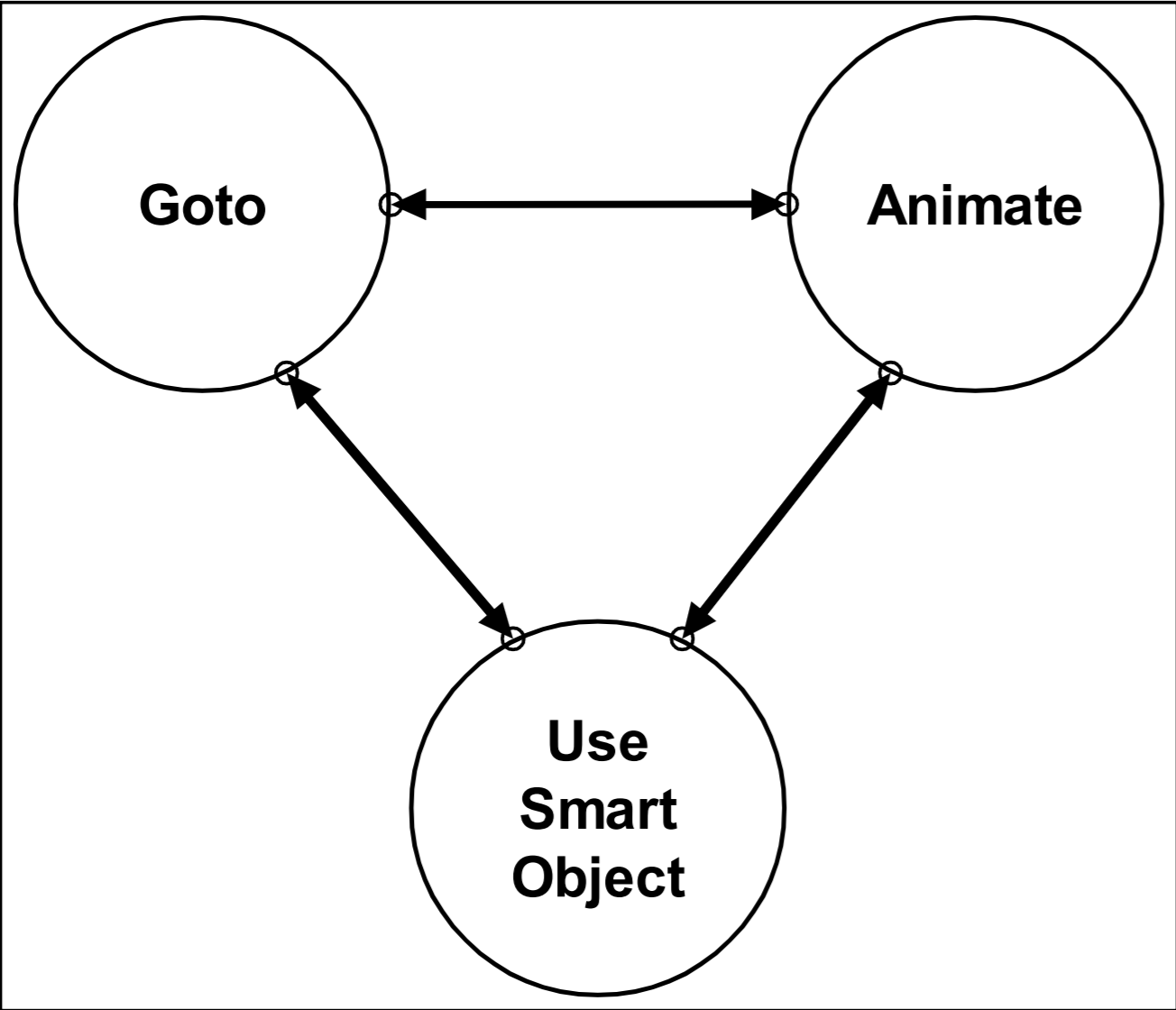
Avec cette approche, l’espace des états est représenté par un automate fini. Contrairement à l’approche classique où l’on défini un automate avec beaucoup d’états qui correspondent tous à une action spécifique, on va définir un petit automate avec seulement quelques états assez abstraits. Chaque état abstrait correspond donc à de grandes catégories d’actions qui seront dépendantes du contexte. Par exemple, les automates finis des PNJs dans F.E.A.R présentent seulement 3 états très abstraits. Un des états permet de gérer les déplacements et les deux autres permettent de gérer les animations. Le comportement complexes des PNJs est donc simplement une succession de déplacements et d’animations.

Les automates finis de F.E.A.R
L’intérêt de l’approche GOAP est que, suivant le contexte dans lequel un objectif est défini, plusieurs plans d’actions différents peuvent être trouvés pour résoudre un même problème. Ce plan d’action est construit à travers les états de l’automate fini qui dictent les mouvements et animations du PNJ.
Quoi qu’il arrive, le plan (la séquence d’actions) trouvé par l’algorithme A* sera toujours une réflexion de l’objectif de l’agent à l’instant présent. Si les objectifs des PNJs sont toujours bien définis, ils présenteront un comportement cohérent, complexe et varié voire parfois surprenant. En effet, ces plans peuvent être plus “long terme” que ceux définis manuellement par un simple automate fini ou un arbre de comportement. C’est pourquoi on peut apercevoir des ennemis se déplacer pour contourner le joueur dans F.E.A.R par exemple.
Cette approche permet d’obtenir des comportements très crédibles dans F.E.A.R, mais elle n’est cependant pas forcément adaptée à tous les types de jeux. En effet, pour des jeux très ouverts et complexes où le nombre d’actions possibles est important la méthode peut présenter des limitations. Dans F.E.A.R, les plans trouvés par l’algorithme de recherche restent relativement courts (en général les séquences ne font pas plus de 4 actions), mais comme les actions et les états sont définis de façon abstraite et haut niveau, une séquence de 4 actions est suffisante pour changer de pièce, contourner le joueur, déplacer des objets, se mettre à couvert etc.. Si un jeu nécessite de trouver des plans avec des séquences d’actions beaucoup plus longues, il est fréquent que l’algorithme soit trop lourd en terme de ressources et que les plans trouvés divergent trop du comportement visé par les concepteurs. En effet, ce genre d’approche apporte moins de contrôle sur le résultat final qu’un arbre de comportement ad hoc par exemple.
C’est le problème qu’ont rencontré les développeurs du jeu Transformers: War for Cybertron en 2010. Ils ont donc décidé de changer d’approche et se sont tournés vers une autre méthode de planning : l’approche Hierarchical Task Network planning (HTN). Pour ceux qui sont intéressés, leurs problématiques et l’implémentation de l’approche sont expliqués dans cet article d’AI and Games (https://aiandgames.com/cybertron-intel/).
Cette approche dans F.E.A.R a été à l’époque de sa sortie une petite révolution dans le monde de l’IA dans les jeux vidéo et elle a depuis été modifiée et améliorée suivant les besoins (avec l’approche HTN par exemple). Par exemple, on retrouve cette approche dans S.T.A.L.K.E.R, Just Cause 2, Tomb Raider, Middle Earth: Shadow of Mordor ou encore Deus Ex: Human Revolution.
Le cas des Jeux de stratégie
Il est évident que, suivant le type de jeu, l’IA n’a pas du tout la même vocation ni les mêmes possibilités. La plupart des méthodes présentées précédemment sont utilisées pour implémenter les comportements d’agents dans un monde dans lequel le joueur évolue. Que ça soit un jeu de tir, ou un jeu de rôle, les PNJ sont en général des personnages similaires au joueur dans le sens ou ils n’ont un contrôle que sur leurs propres actions. De plus, un comportement planifié à court ou moyen terme (4 actions pour F.E.A.R) est souvent suffisant pour présenter un comportement satisfaisant.
Il existe cependant d’autres types de jeu (notamment les jeux de stratégie) où un agent qui joue au jeu doit contrôler plusieurs unités en même temps et mettre en place des stratégies sur le très long terme pour pouvoir se défaire de ses adversaires. Ce genre de jeux peut se rapprocher des jeux de plateaux comme les échecs ou le Go. À un instant donné, un agent peut effectuer un très grand nombre d’actions possibles. Les actions possibles, pertinentes ou non, sont dépendantes de l’état actuel du jeu (qui lui découle de toutes les actions prises précédemment par le joueur et son adversaire).

Dans un jeu comme Starcraft II, le nombre d’unités à contrôler et le nombre de décisions à prendre est très important.
Dans ce genre de jeu, l’espace des états correspond à l’ensemble des configurations possibles dans lequel peut se retrouver le jeu. Plus le jeu est complexe, plus cet espace est grand et plus il est difficile pour une IA d’y jouer.
En effet, pour pouvoir jouer à ce genre de jeu, une IA doit parcourir l’espace des états pour estimer la pertinence des différentes actions possibles. Pour un jeu comme les échecs il est encore possible de rechercher dans l’espace des états (de taille 10^47) mais pour des jeux plus compliqués comme le Go cela devient impossible en terme de puissance de calcul. Le Go présente environ 10^170 états. En comparaison, le jeu de stratégie en temps réel Starcraft II a un espace des états estimé à 10^1685. Pour donner une idée, on estime qu’il y a environ 10^80 protons dans l’univers observable.
Pendant longtemps l’IA n’était pas capable de battre les meilleurs joueurs aux jeux de plateau comme les échecs (ce n’est qu’en 1997 que l’IA Deep Blue a réussi à battre Kasparov, le champion du monde d’échecs). Le jeu de Go n’a quant à lui été “résolu” qu’en 2016 grâce, entre autres, à l’émergence du Deep Learning. Autant dire que les méthodes de recherche et de planning (comme GOAP dans F.E.A.R) ne peuvent pas fonctionner pour les jeux comme Starcraft et que les développeurs ont dû trouver d’autres solutions.
Les IA des jeux de stratégie ont donc été basées sur des approches plus simplistes ou chaque unité présentait un comportement indépendant des autres. Si chaque unité est prise indépendamment, son espace des états est beaucoup plus réduit et il devient possible de le représenter par une méthode ad hoc (comme un automate ou un arbre de comportement) ou de faire une recherche dedans pour trouver une séquence d’action (de la même façon que pour les PNJs des jeux de tir par exemple).
Avec cette approche, il devient possible de calculer les comportements de toutes les unités, mais l’IA ne peut pas vraiment présenter de stratégie globale, les différentes unités ne pouvant pas se coordonner. Ces IAs sont donc en général incapables de battre des joueurs aguerris.
C’est la difficulté de la tâche qui a souvent amené les développeurs de ces IAs à tricher, seule solution pour pouvoir présenter un quelconque challenge au joueur. C’est parfois toujours le cas aujourd’hui suivant le type de jeu. Par exemple dans Starcraft II (sortie en 2010), les niveaux de difficulté les plus élevés pour le joueur sont gérés par des IA qui trichent.

Les différentes niveaux de difficulté de l’IA dans Starcraft II
Les développeurs de Starcraft II jouent ici la transparence sur leur IA. Tout joueur qui se risque contre le niveau de difficulté le plus élevé sait à quoi s’attendre. Malgré cette triche, l’IA du jeu reste prévisible et les bons joueurs arrivent à s’en défaire sans trop de difficulté.
Monte Carlo Tree Search à la rescousse
Récemment, une nouvelle méthode a fait beaucoup parler d’elle pour ce genre de problématiques où l’espace à rechercher est très grand. Il s’agit de la méthode Monte Carlo Tree Search. Utilisée pour la première fois en 2006 pour jouer au Go, elle a rapidement permis d’améliorer les systèmes de l’époque (qui ne pouvaient pas encore rivaliser avec un joueur amateur). Puis plus récemment en 2016, elle a été utilisée comme une des briques principales d’AlphaGo, l’algorithme qui a réussi à vaincre le champion du monde de Go.
Cette méthode peut aussi bien sur être appliquée aux jeux vidéo. Elle a notamment été utilisée pour le jeu Total War : Rome II sorti en 2013.
Les jeux de la série Total War présentent différentes phase de jeux:
- Une phase de stratégie au tour par tour sur une carte du monde ou chaque joueur doit gérer son pays ainsi que les relations avec les pays alentours (diplomatie, guerre, espionnage etc..).
- Une phase de bataille en temps réel à une échelle rarement vue dans les jeux vidéo (chaque camp présente souvent plusieurs milliers d’unités).
La phase au tour par tour présente un espace des états très grand dans lequel il n’est pas possible de rechercher des séquences d’actions et donc des stratégies pertinentes. C’est dans cette phase de jeu que la méthode MCTS peut aider. En effet, comme cette phase se déroule au tour par tour, il est possible de prendre un peu de temps pour trouver une bonne solution. Ici le système d’IA n’est pas obligé de répondre en quelques millisecondes comme c’est souvent le cas.
La méthode MCTS permet de rechercher efficacement des solutions dans un espace impossible à parcourir entièrement. La méthode se base sur des notions d’apprentissage par renforcement, particulièrement le dilemme exploration-exploitation. L’exploitation consiste à parcourir les branches de l’arbre que l’on pense être les plus pertinentes pour trouver la meilleure solution. L’exploration à l’inverse consiste à parcourir de nouvelles branches que l’on ne connaît pas ou que l’on avait préalablement considérés comme non pertinentes.
Il peut sembler logique de ne vouloir faire que de l’exploitation, c’est-à-dire toujours se focaliser sur les solutions que l’on pense être les meilleures. Cependant la méthode MCTS est utilisée dans les cas où il n’est pas possible de rechercher l’ensemble des solutions puisque l’arbre est trop grand (sinon on utilise un algorithme comme le minimax). Dans ce cas là il n’est pas possible de savoir si la solution que l’on considère est vraiment la meilleure. Peut-être qu’une autre partie de l’arbre non parcourue contient de meilleures solutions. De plus, une branche non pertinente à un moment donné, peut le devenir plus tard, c’est pourquoi si l’on fait seulement de l’exploitation on risque de rater des solutions intéressantes. La méthode MCTS permet de trouver un compromis entre exploration et exploitation afin de trouver rapidement des solutions satisfaisantes.

La méthode MCTS présente une recherche asymétrique : elle parcourt beaucoup plus souvent les branches qui semblent intéressantes par rapport aux autres branches.
L’algorithme MCTS peut être découpé globalement en 4 phases répétées un grand nombre de fois. Tout d’abord, l’idée est de parcourir de façon intelligente l’espace des états depuis la racine jusqu’à atteindre un noeud feuille de l’arbre (c’est la phase de Sélection - voir figure ci-dessous). Ensuite, l’algorithme choisit une action à effectuer, c’est la phase d’Expansion. Une fois cette action choisie, l’idée est et de simuler le jeu en choisissant un enchaînement d’actions de façon aléatoire jusqu’à arriver à la fin du jeu. C’est la phase de Simulation. Et enfin, en fonction du résultat final du jeu (victoire ou défaite), l’algorithme évalue si le noeud choisi à l’étape d’Expansion était pertinent ou non et il pondère tous les noeuds parcourus lors de cette simulation en fonction du résultat. C’est la phase de Backpropagation

Dans l’exemple de l’image ci-dessus, le joueur noir a le choix entre trois actions possibles. Pour chaque noeud, on compte le nombre de fois ou la partie a été gagné durant les simulations. L’action de gauche est plus prometteuse puisqu’elle a permis de gagner 7 fois sur 10. C’est pourquoi la branche de gauche est la plus souvent explorée.
L’objectif de l’étape de Backpropagation est de faire en sorte que les noeuds qui semblent les plus pertinents soient choisis plus fréquemment lors des prochaines étapes de Sélection. C’est lors de la phase de Sélection que le compromis entre exploration et exploitation est fait.
L’idée de la méthode MCTS est de lancer des milliers de fois ces quatre étapes de simulations et au moment de prendre une décision, de choisir le noeud qui a donné au total le plus de victoires sur l’ensemble les simulations
L’avantage de la méthode est que l’on peut définir un temps d’exécution maximal. Jusqu’à la limite de temps alloué, l’algorithme va lancer des simulations. Une fois le temps écoulé il suffit de prendre le noeud avec le plus grand taux de victoire. Plus on lui laisse de temps, plus il y a de chances qu’il trouve de bonnes solutions puisque les statistiques calculées seront précises.
Ainsi, la solution finalement trouvée par MCTS ne sera peut-être pas la solution optimale mais elle sera la meilleure solution trouvée dans le temps imparti.
Cette approche a permis à l’agent qui joue à la phase de stratégie tour par tour de Rome II Total War de présenter des stratégies relativement poussées malgré la complexité très importante de l’espace des états du jeu.
De façon amusante, le système d’IA pour les batailles en temps réel se base quant à lui sur des méthodes ad hoc tirées de l’Art de la Guerre de Sun Tzu (environ 500 avant J-C).

Une citation pertinente même pour un système d’IA
Ces règles de stratégie peuvent aussi être appliquées avec succès dans un jeu vidéo. Par exemple:
- Quand vous entourez l'ennemi, laissez une porte de sortie
- N'essayez pas de bloquer la route de l'ennemi sur un terrain dégagé
- Si vous êtes 10 fois plus nombreux que l'ennemi, entourez-le
- Si vous êtes 5 fois plus nombreux que l’ennemi, attaquez-le de front
- Si vous êtes 2 fois plus nombreux que l'ennemi, divisez-le
Ces règles simples peuvent facilement être implémentées dans un système ad hoc et permettent à l’IA de présenter un comportement pertinent dans bon nombre de situations et donc de proposer des batailles réalistes.
Et le Machine Learning dans tout ça ?
Toutes les méthodes présentées jusqu’ici ne proposent pas d’apprentissage. Les comportements sont régis par des règles définies manuellement et par la façon de considérer ces règles en fonction de l’environnement. Pour obtenir des IA plus complexes qui peuvent vraiment s’adapter à des situations variées, il semble nécessaire de mettre en place des systèmes qui peuvent apprendre automatiquement à agir en fonction du comportement du joueur.
La branche d’apprentissage automatique en IA s’appelle le Machine Learning.
Des méthodes d’apprentissage automatiques ont parfois été utilisées pour coder le comportement d’agents. Par exemple les unités dans les batailles temps réel des jeux Total War sont contrôlées par des perceptrons (les réseaux de neurones ancêtres du Deep Learning). Dans ce genre d’implémentation les réseaux sont très simples (on est loin des réseaux énormes du Deep Learning).
Les entrées des réseaux correspondent à l’état du jeu (la situation) et les sorties correspondent à l’action prise. L’apprentissage de ces réseaux est fait en amont pendant le développement du jeu (parfois même manuellement pour les réseaux les plus simples). Ce genre de méthode se rapproche au final des méthodes ad hoc puisque le comportement des unités est fixé par le développeur et qu’il n’évolue pas pendant le jeu.
Il y a cependant eu des cas où les agents pouvaient vraiment apprendre pendant le jeu. Par exemple dans Black and White (sorti en 2000) qui est réputé pour avoir réussi à mélanger différentes approches d’IA en obtenant un résultat performant. Le principe du jeu se base beaucoup sur l’interaction entre le joueur et une créature ayant un comportement complexe.
Le comportement de prise de décision de la créature est modélisé selon un agent “croyance-désir-intention” (belief-desire-intention - BDI). L’approche BDI est un modèle de psychologie, qui est ici adapté pour les jeux vidéo.

Le modèle DBI
Cette approche comme son nom l’indique modélise, pour un agent, un ensemble de croyances, de désirs et d’intentions qui dictent sa prise de décision.
Les croyances correspondent à l’état du monde vu par l’agent. Ces croyances peuvent être fausses si l’agent n’a pas accès à toutes les informations. Les désirs, basés sur les croyances, représentent les motivations de l’agent et donc les objectifs court et long terme qu’il va chercher à atteindre. Les intentions sont les plans d’action que l’agent a décidé d’exécuter pour atteindre ses objectifs.
Dans Black and White, les croyances de la créature sont modélisés par des arbres de décision et les désirs sont modélisés par des perceptrons. Pour chaque désir, la créature se base sur ses croyances les plus pertinentes.
Le modèle BDI représente le système de prise de décision de la créature, mais au début du jeu, elle est comme un enfant dont les croyances et les désirs ne sont pas bien définis. Au cours du jeu, la créature apprend à se comporter à travers ses interactions avec le joueur. En effet, le joueur peut récompenser la créature ou la punir en fonction de ses actions. À travers un algorithme d’apprentissage par renforcement la créature va découvrir quelles actions entraînent une récompense et lesquelles entraînent une punition. Cela va donc modéliser son comportement pour être en accord avec ce que lui demande le joueur.

La créature de Black and White
Le système comportemental de la créature est donc un système hybride basé sur un socle d’IA ad hoc (le modèle BDI) pour lequel chaque composant est un algorithme d’apprentissage automatique. Ces systèmes hybrides sont probablement le meilleur compromis pour obtenir des comportements complexes et évolutifs mais qui restent quand même dans un cadre défini initialement.
Si ça marche, pourquoi on reste sur de l’ad hoc ?
Ce genre d’approche plus poussée avec de l’apprentissage automatique ne représentent cependant vraiment pas la majorité des implémentations dans les jeux vidéo, et la plupart des IA reconnues comme très performantes récemment comme par exemple l’IA du compagnon dans Bioshock Infinite sont en général plutôt des systèmes ad hoc très complexes et très bien pensés pour rentrer parfaitement dans le gameplay du jeu (avec toutes les triches que cela peut nécessiter, comme la téléportation du compagnon quand le joueur ne peut pas le voir par exemple).
Si les développeurs continuent de se raccrocher aux méthodes classiques d’IA ad hoc, c’est premièrement parce qu’au final, ces méthodes fonctionnent bien (par exemple dans F.E.A.R ou Bioshock Infinite). En effet, ce que les concepteurs cherchent à créer est une illusion d’intelligence qui soit crédible pour le joueur, même si le modèle qui gère les PNJs est au final très simple. Tant que l’illusion est présente, le contrat est rempli. Cependant mettre en place ce type de système peut en fait vite devenir d’une grande complexité suivant le type de jeu et donc nécessiter un temps et des ressources de développement très importants. La majorité des déboires de l’IA dans les jeux vidéo est probablement due à un investissement dans le développement de l’IA trop faible plutôt qu’à des méthodes non adaptées.
La deuxième raison importante qui force les développeurs à rester sur des systèmes sans apprentissage est la difficulté à prévoir le comportement des IA dans toutes les situations. Les concepteurs de jeu craignent qu’une IA qui apprend automatiquement puisse briser l’expérience de jeu du joueur en présentant un comportement non prévu et incohérent qui sortirait le joueur de son immersion dans l’univers du jeu (on peut noter que c’est cependant justement ce qui se passe avec un système d’IA ad hoc mal implémenté). Les designers veulent imaginer intégralement l’expérience que vivra le joueur et c’est beaucoup plus difficile à définir avec une IA qui apprend automatiquement.
Un autre point important est que le comportement du PNJ se doit d’être un minimum prévisible et présenter des codes qui sont connus et attendus par les joueurs. Ces codes de comportements sont hérités des premiers jeux qui ont défini les styles et de leur évolution.
Par exemple, en général dans les jeux d’infiltration les gardes font des rondes en suivant un schéma spécifique que le joueur doit mémoriser pour pouvoir passer sans se faire voir. En implémentant avec une IA un comportement plus complexe on peut risquer de changer l’expérience classique des jeux d’infiltration et c’est donc un choix à faire en connaissance de cause. Un autre cas similaire est le combat de boss. Dans de nombreux jeux les combats contre les boss sont des phases particulières ou le boss à un comportement prédéterminé qui doit être compris par le joueur pour pouvoir gagner.

Un combat de boss dans super metroid
Un boss qui s’adapterait trop à la façon de jouer du joueur pourrait surprendre les joueurs formatés par leurs expériences passées. En implémentant une IA dans un jeu, il faut être capable de le faire tout en jouant avec les nombreux clichés du médium. C’est pourquoi les approches les plus innovantes en terme d’IA de nos jours sont souvent liées à de nouveaux concepts de jeux, les styles classiques étant parfois considérés trop rigides pour accueillir ce genre d’IA.
Enfin, une autre raison de rester sur des méthodes ad hoc semble être que l’on a toujours fait comme cela dans le domaine, et que se mettre à innover sans assurance de succès dans un cadre aussi restreint en terme de temps et de ressources que le développement d’un jeu vidéo semble être un risque assez conséquent à prendre. Surtout pour des studios de développement dont la santé peut dépendre du succès ou non d’un seul jeu.
L’évolution des méthodes
Comme on a pu le voir les méthodes d’IA dans les jeux vidéo ont évolué sans cesse au cours du temps pour devenir de plus en plus complexes et poussées. On peut ainsi se demander pourquoi lorsque l’on joue, on a la sensation que l’IA stagne et qu’elle ne s’améliore pas vraiment.
La réponse est très probablement que les jeux deviennent de plus en plus grands et compliqués et donc que les tâches que les IAs doivent résoudre pour être cohérentes sont de plus en plus complexes.
Ainsi, les jeux dont l’IA a été un franc succès sont souvent des jeux ou le domaine était relativement réduit. Par exemple dans F.E.A.R qui se focalise sur des affrontements à petite échelles. Plus les jeux sont ouverts, plus il y a de chances que l’IA soit prise en défaut. On peut prendre l’exemple de l’IA des bandits dans le jeu de rôle Skyrim.

Ceux-ci présentent des failles assez évidentes qui peuvent amener au genre de situations incongrues dépeintes par l’image ci-dessus. Le problème dans Skyrim est que l’IA des PNJs doit être capable de gérer un nombre très grand de situations différentes, il y a donc très probablement des situations où elle ne sera pas adaptée.
Un autre problème dans les jeux trop grands est que la quantité de contenu à générer pour que ce monde soit cohérent devient très importante. Si on veut que chaque PNJ soit unique et présente une histoire qui lui est propre, cela représente un travail énorme. C’est pourquoi l’ensemble des gardes dans Skyrim ont tous pris une flèche dans le genou dans leur jeunesse quand ils étaient aventuriers.
L’IA peut nous aider face à cette problématique de contenu grâce à ce que l’on appelle la génération procédurale de contenu. Dans le 3ème article nous nous intéresserons donc à d’autres façon moins fréquentes d’implémenter de l’IA dans des jeux vidéo, et notamment avec la génération procédurale de contenu.
Références :
Stuart Russell and Peter Norvig. 2009. Artificial Intelligence: A Modern Approach (3rd ed.). Prentice Hall Press, Upper Saddle River, NJ, USA.
Yannakakis, Georgios N., and Julian Togelius.
Artificial Intelligence and Games. Springer, 2018.
http://sitn.hms.harvard.edu/flash/2017/ai-video-games-toward-intelligent-game/
https://aiandgames.com/
http://alumni.media.mit.edu/~jorkin/gdc2006_orkin_jeff_fear.pdf
http://mcts.ai/pubs/mcts-survey-master.pdf
Images:
https://www.computing.dcu.ie/~humphrys/Notes/Morelli.images/1.gif
https://cdn-images-1.medium.com/max/1600/1*cgtTkA2_PvU5-ZMb2fPA-g.png
https://cdn.arstechnica.net/wp-content/uploads/sites/3/2016/11/Legacy-12-980x551.jpg
http://i.imgur.com/8xiTj5v.jpg
https://nb4799.neu.edu/wordpress/wp-content/uploads/2018/04/Screenshot-from-2018-04-14-22-34-25.png
https://upload.wikimedia.org/wikipedia/commons/thumb/6/62/MCTS_%28English%29-_Updated_2017-11-19.svg/808px-MCTS%28English%29_-_Updated_2017-11-19.svg.png
https://i.pinimg.com/originals/13/3a/d2/133ad293cc82b6e7a446721a97db12e0.jpg
https://www.researchgate.net/profile/Luis_Rodrigo_Barba_Guaman/publication/313617511/figure/fig1/AS:460855604191232@1486887946569/Belief-Desire-Intention-model-for-reasoning-procedure.png
https://www.researchgate.net/profile/Clinton_Heinze/publication/228617498/figure/fig1/AS:393742692438016@1470886981124/Screenshot-of-a-curious-tiger-interacting-with-your-creature-in-Black-White-Lionhead.png
http://image.jeuxvideo.com/images/wu/s/u/super-metroid-wii-u-wiiu-1368726239-011.jpg
https://www.deviantart.com/t3ragram/art/Skyrim-Sneaking-274805514
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}